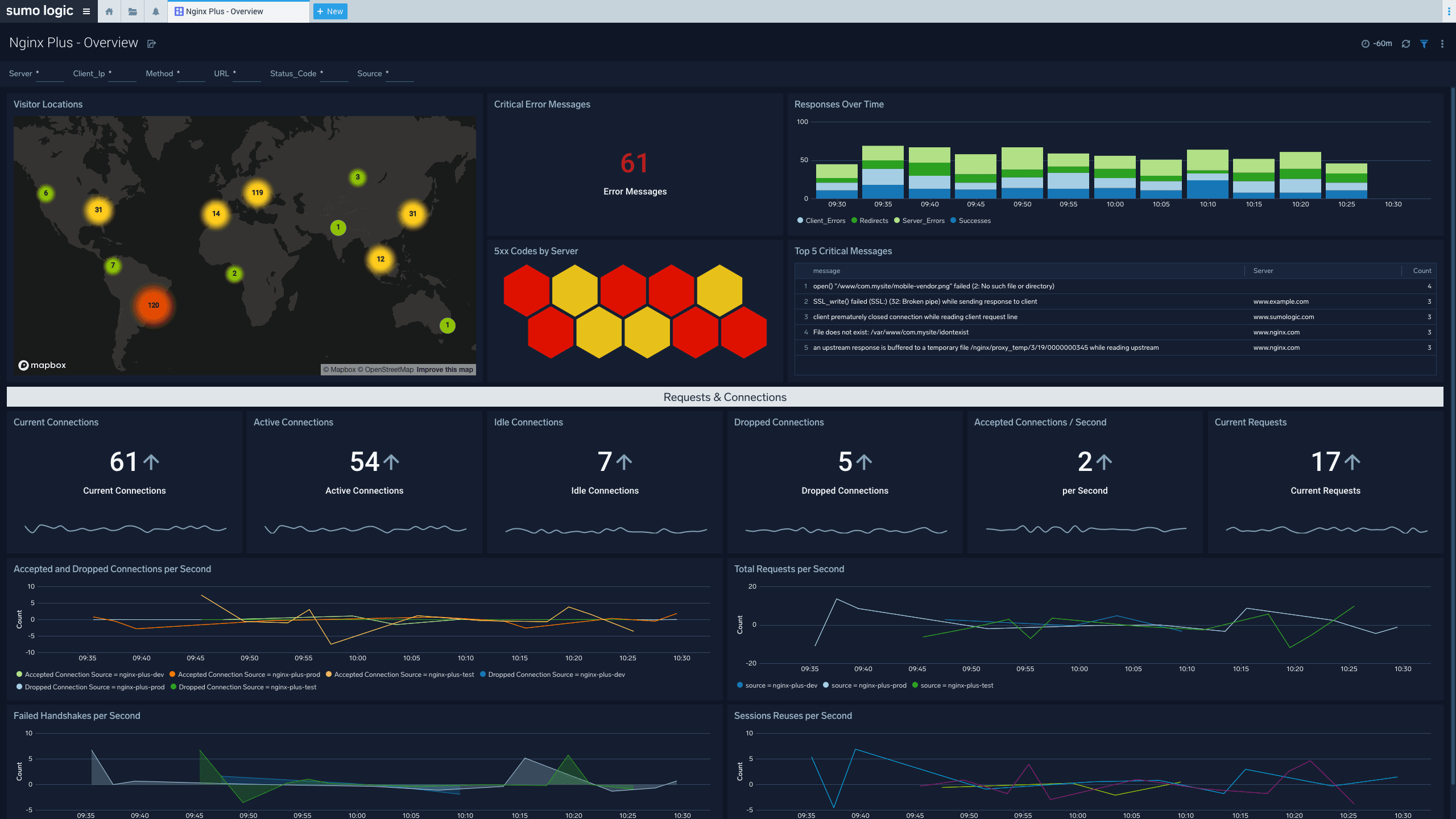
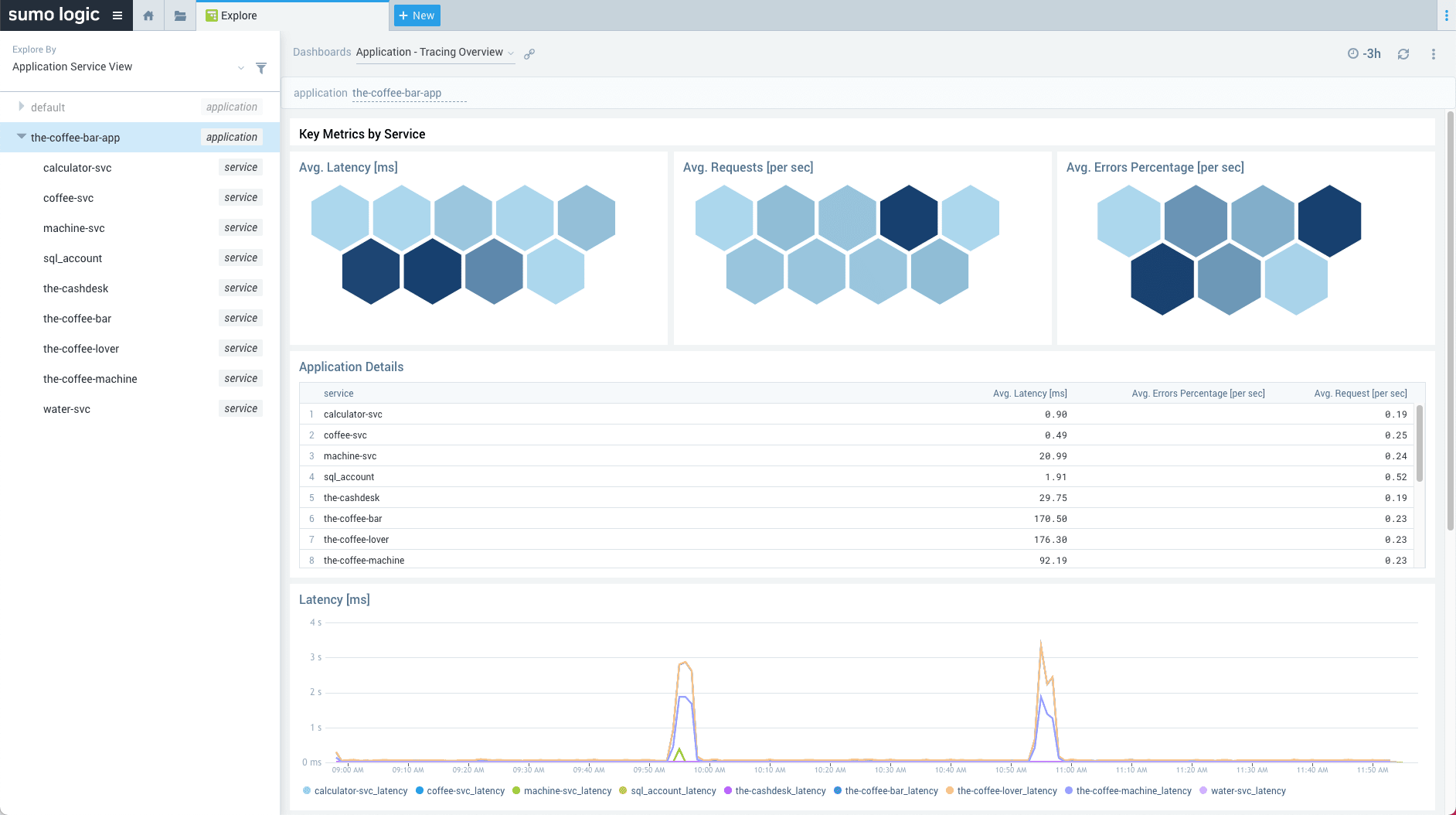
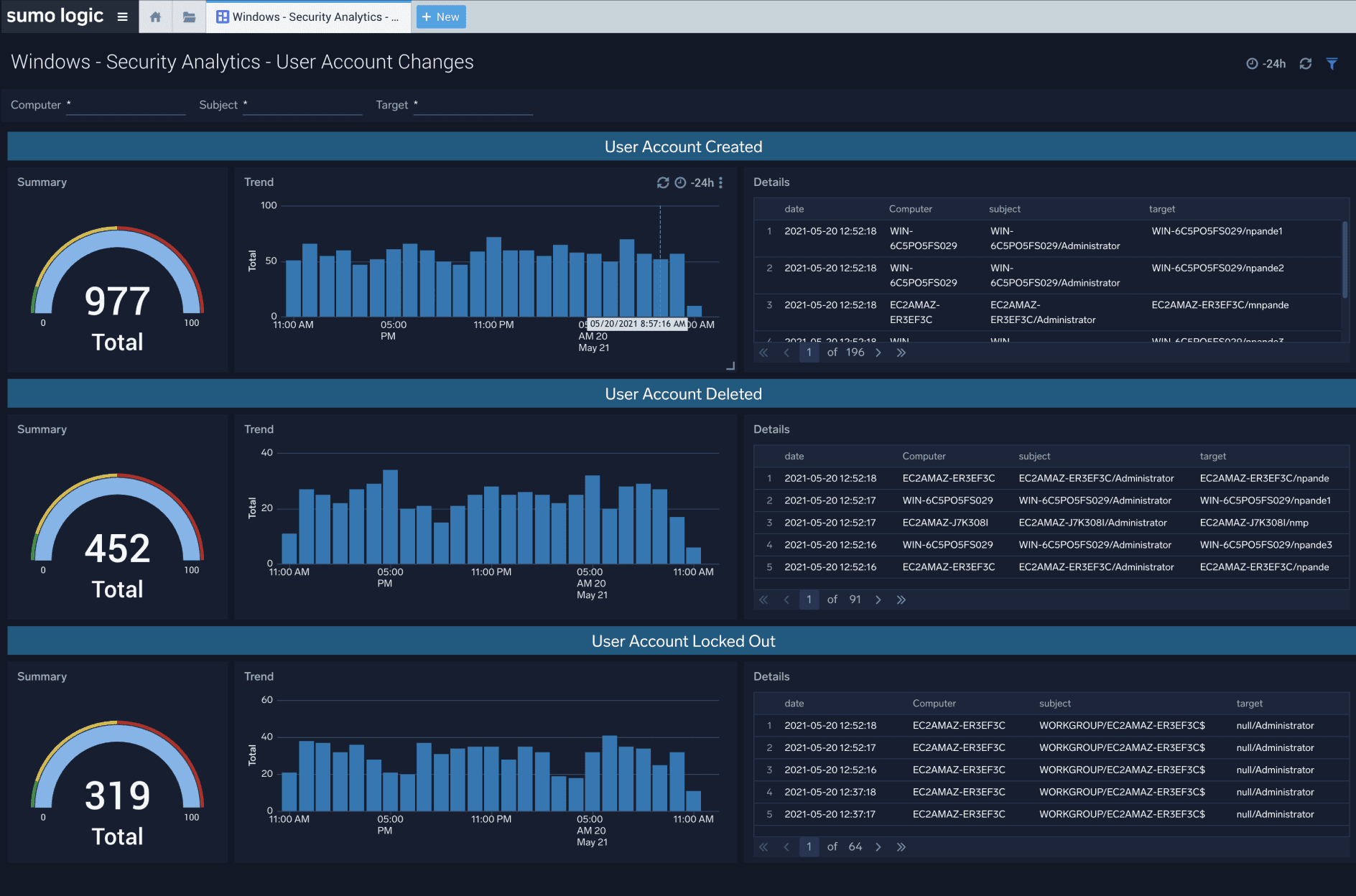
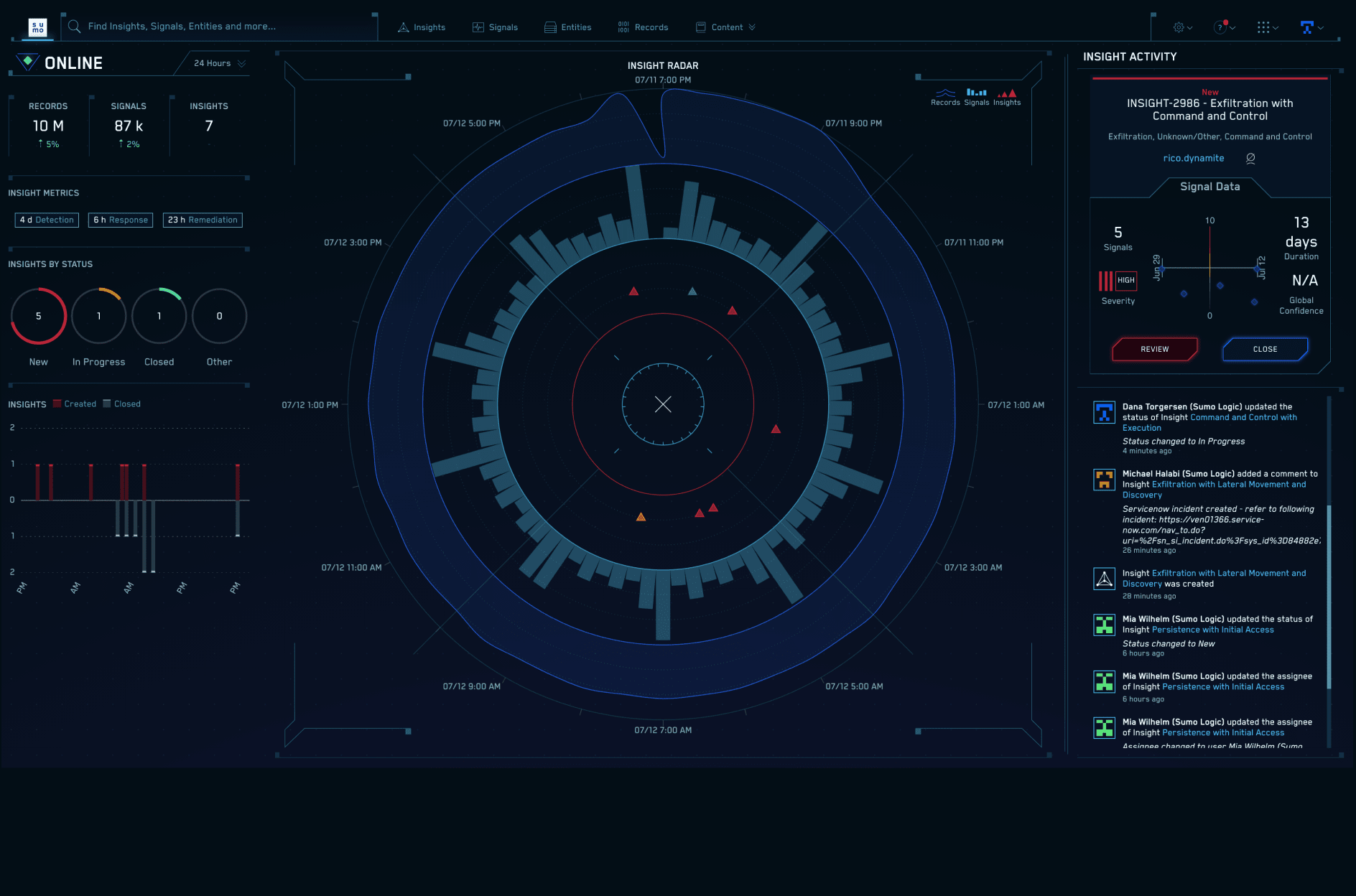
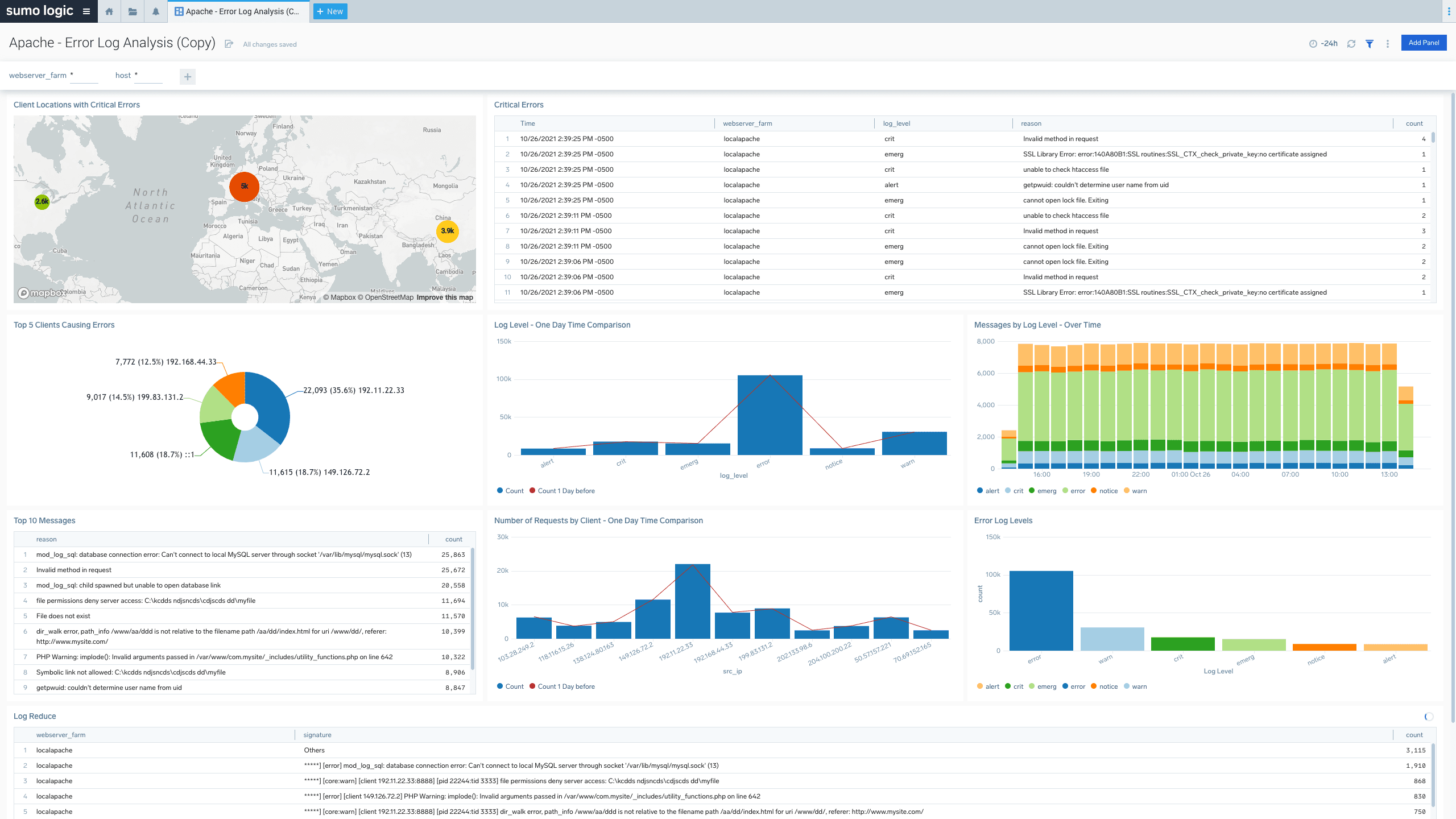
Log Analytics
Break down silos with a modern log management solution to improve monitoring and troubleshooting, increase security posture, and gain key business insights.
Key features:
- Secure, compliant platform
- Unlimited queries
- Historical & live streaming dashboards
- Real-time alerts
- Log Reduce for immediate key insight analytics
- 1-click integrations with AWS, Azure, & GCP
- Standard support
Available as part of the following subscription packages (pricing varies by package): Enterprise Suite, Enterprise Security, Enterprise Operations, Essentials
See packagesStarting at $3,00/GB*
*The price per GB is calculated assuming Customer purchases: (1) an annual commitment to Sumo Logic Essentials; (2) ingesting an average of 1GB of log ingest per day; and (3) election of a US Deployment Region. Pricing may vary based on Deployment Region selected by Customer.