
2022 Gartner® Magic Quadrant™ SIEM
Get the report
MoreTrusted by thousands of customers globally.
Browse our library of ebooks, briefs, reports, case studies, webinars & more.
November 6, 2022

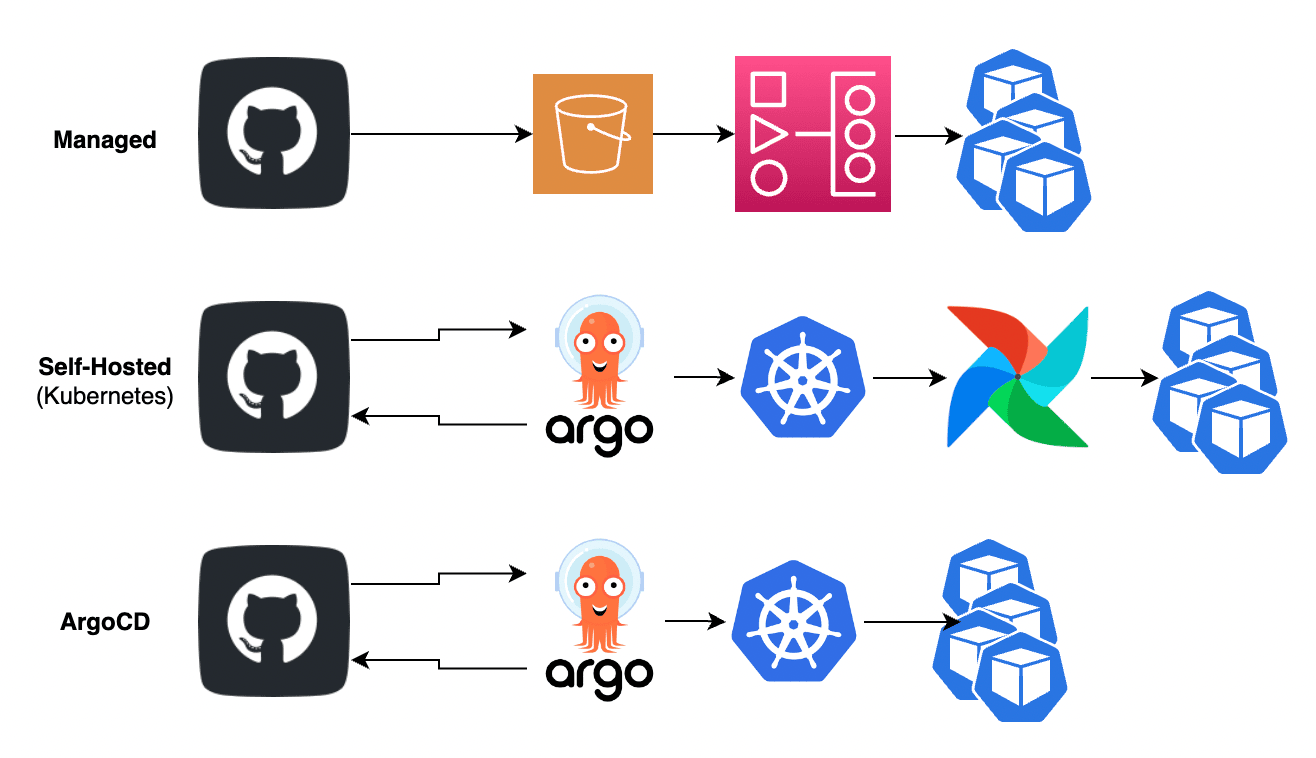
Apache Airflow is an open-source orchestration platform that enables the development, scheduling and monitoring of tasks using directed acyclic graphs (DAGs). Here at Sumo, our team has been using this technology for several years to manage various jobs relating to our organization’s Global Intelligence, Global Confidence, and other data science initiatives. We self-host the tool through Kubernetes. However, back in 2020 as the new Airflow v2 was released our team began facing problems trying to migrate to the newest version:
Several operators and utility functions that our team defined used features that were refactored or no longer supported.
Our database needed to be migrated to a new version which is not supported by our current implementation of Airflow.
When coming across big migration tasks such as these, it’s always a good idea to take a look at other alternatives which may be more suitable or easier to implement. You may even look for a different way to solve the same problem.
Our team looked at three different migration paths:
Amazon Managed Workflows for Apache Airflow (MWAA): a fully managed service offering by AWS
Kubernetes using a common helm chart: essentially a repeat of our Airflow v1
ArgoCD Workflows: we already utilize Argo to manage various CI/CD pipelines, so this seemed like an easy pivot to make
In order to ensure that we picked the best possible approach for our use case, our team identified a few key components which we wanted to focus on, please note that for your team the components may be different:
Visibility: How easy is it for us to view failed jobs? The current status of a job? How often a job is retired? Compute analytics about our job runtimes?
Upgrades: How do we handle future upgrades when needed?
DAG development: How easy is it to develop or iterate on DAGs? Can we test any component locally before pushing it upstream?
DAG deployment: How do we propagate updates to different environments? What are the artifacts we need to generate to identify a single release candidate?
Feature flags: Can we hide certain features from certain deployments? Can we override environment variables easily?
Scalability: What’s the process behind scaling or dividing resources for individual DAGs
Cost: What’s the cost per run? How is it computed?
These are our findings:
Kubernetes |
AWS MWAA |
ArgoCD |
|
State management |
All states for DAGs are stored in a database which we also need to manage. |
Similarly to Kubernetes data is stored in RDS, but the actual hosting of this database is abstracted away from us |
State is stored inside of Kubernetes. This means that it is short-lived unless we configure the cluster to save it indefinitely but at an increased complexity. |
Upgrades |
While we could face the same problems in upgrading to future versions of Airflow. We can incorporate a lot of the learnings from the older implementation and ensure that we limit the use of non-standard definitions to a minimum. |
Upgrades are not done in place, and each upgrade would require a deployment of a new Airflow Environment. |
Upgrades are handled by a separate internal team that handles our Kubernetes cluster. So we would be dependent on other teams to ensure that we get them |
DAG development |
DAGs are just python scripts, which means that development can be achieved locally. |
Same as Kubernetes. |
DAGs are defined in YAML files, and in order to test changes we have to push them into a cluster, which makes testing and developing more complex. |
DAG deployment |
DAGs are synced by watching over a specific git commits. So updates can be managed by generating tags. |
Updates to DAGs are handled by pushing the code to an s3 bucket which is then synced with the deployment |
Same as Kubernetes. |
Feature flags |
Feature flags can be managed via Variables that can be synced with helm through |
Feature flags could be propagated through either: |
Flags can be propagated through |
Scalability |
We control how much we want to scale the worker numbers. Our constraints tie directly to how many resources are available for us. |
Maximum capacity of concurrently running DAGs is 1000 (on the highest region tier): Amazon MWAA automatic scaling - Amazon Managed Workflows for Apache Airflow This is not a hard limit as we can request increases in the number of workers using request quota increases which will allow us to scale the instances further Amazon MWAA frequently asked questions - Amazon Managed Workflows for Apache Airflow |
Same as Kubernetes. |
Cost |
Cost would encompass the RDS costs and Kubernetes hosting costs (which is observed by the team managing the Kubernetes cluster). |
Cost depends on the type of environment, worker, scheduler and storage we define. |
The cost is observed by the team managing the Kubernetes cluster. |
Based on this analysis, we eliminated ArgoCD Workflows first. ArgoCD seems to have an incomplete development experience as it requires a local Kubernetes cluster to be spun up, and most of the tests are written as end-to-end tests rather than a clear way to test individual units, whereas Airflow DAGs are written in python which means that smaller components can be tested directly using pytest or unittest. Additionally, our team found that going forward the templating language used in Argo, which is based on golang templates is much harder to maintain and read than python. Especially since our team spends more time writing python code for our models than it does using golang.
Next, we’ve decided to go with the Kubernetes approach instead of using the AWS managed solution as we found that scaling out workers is more dynamic in the Kubernetes approach, feature flagging can be tackled using an existing style that our team already knows how to handle. Additionally, DAGs are synced directly from the source as opposed to using an s3 bucket as a middle man, which means that we can potentially do rollbacks and upgrades by just changing the commit reference. Lastly, AWS does not guarantee upgrades to be done more simply than what we would have to do with Kubernetes, it seems to require about the same amount of work, since we would still need to go through spinning up a new environment each time we want a new version.
In conclusion, we’ve opted for using Airflow in Kubernetes using this helm chart, which we recommend you check out as well. A last note, which we didn’t mention in the table but later discovered was a very big nice to have, is that going with the Kubernetes approach also meant that we could leverage our own organization for monitoring and alerting, you can read more about our Kubernetes Monitoring.
Reduce downtime and move from reactive to proactive monitoring.
Build, run, and secure modern applications and cloud infrastructures.
Start free trialSenior Machine Learning Engineer
Ariel Sosnovsky is a machine learning specialist with 5+ years of experience with varying data science projects and infrastructure engineering. In his spare time he loves to tinker with home automation projects while spending time with his family (he’s got a 1 year old). He also has developed some open source projects which have gained mild notoriety (see Shortumation, and pdfmajor) as well as contributed to few popular ones.
More posts by Ariel Sosnovsky.

No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.
