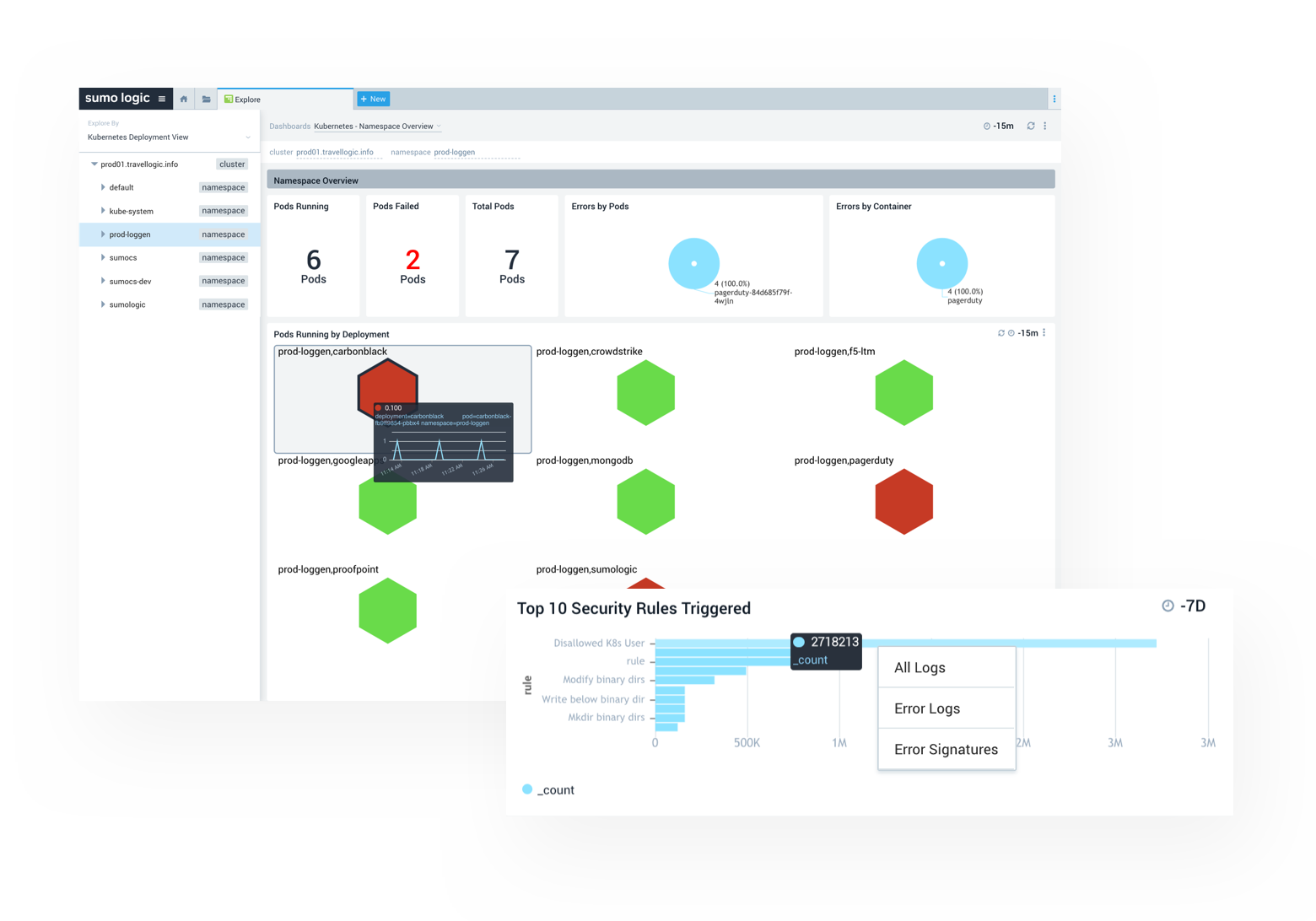
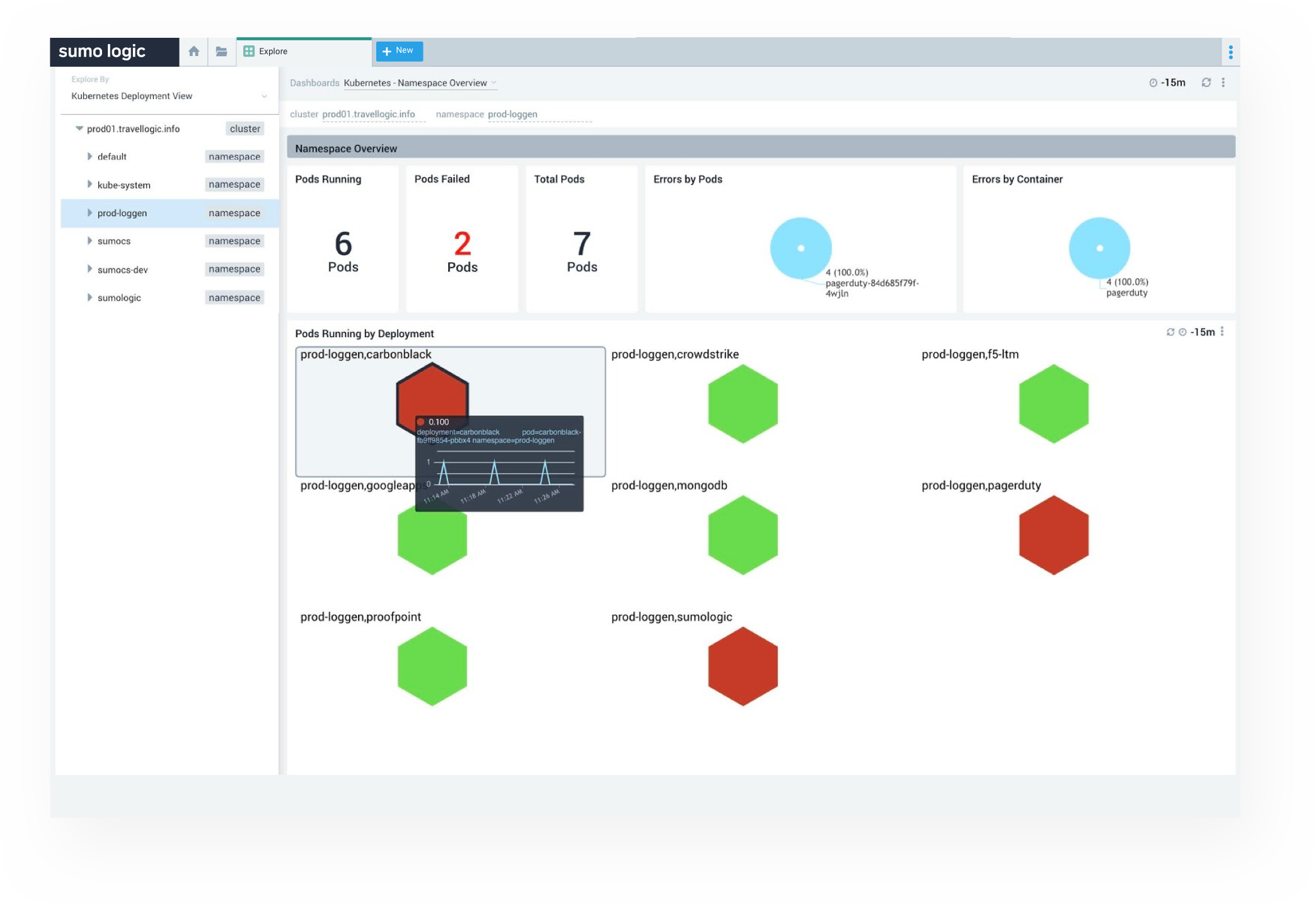
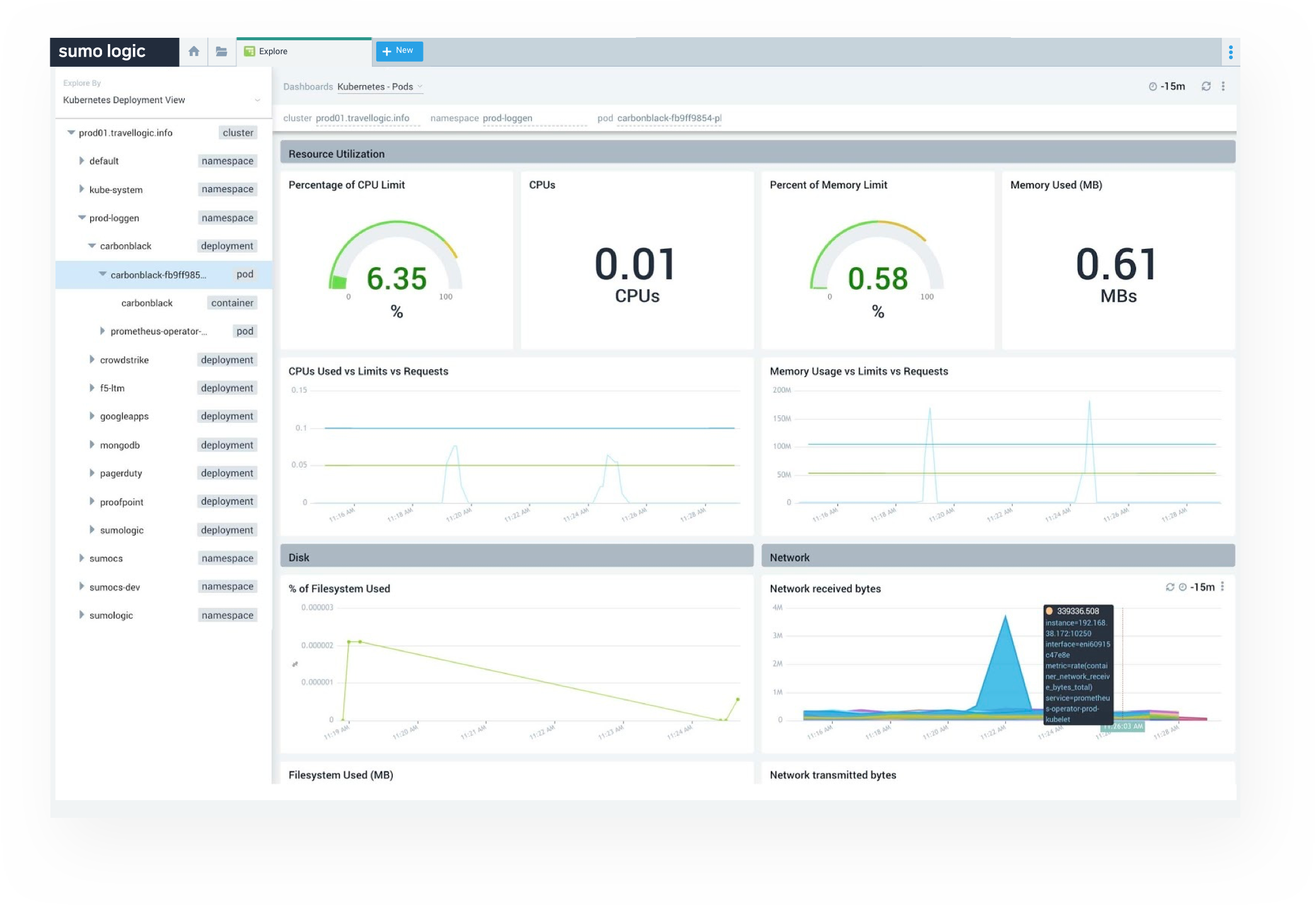
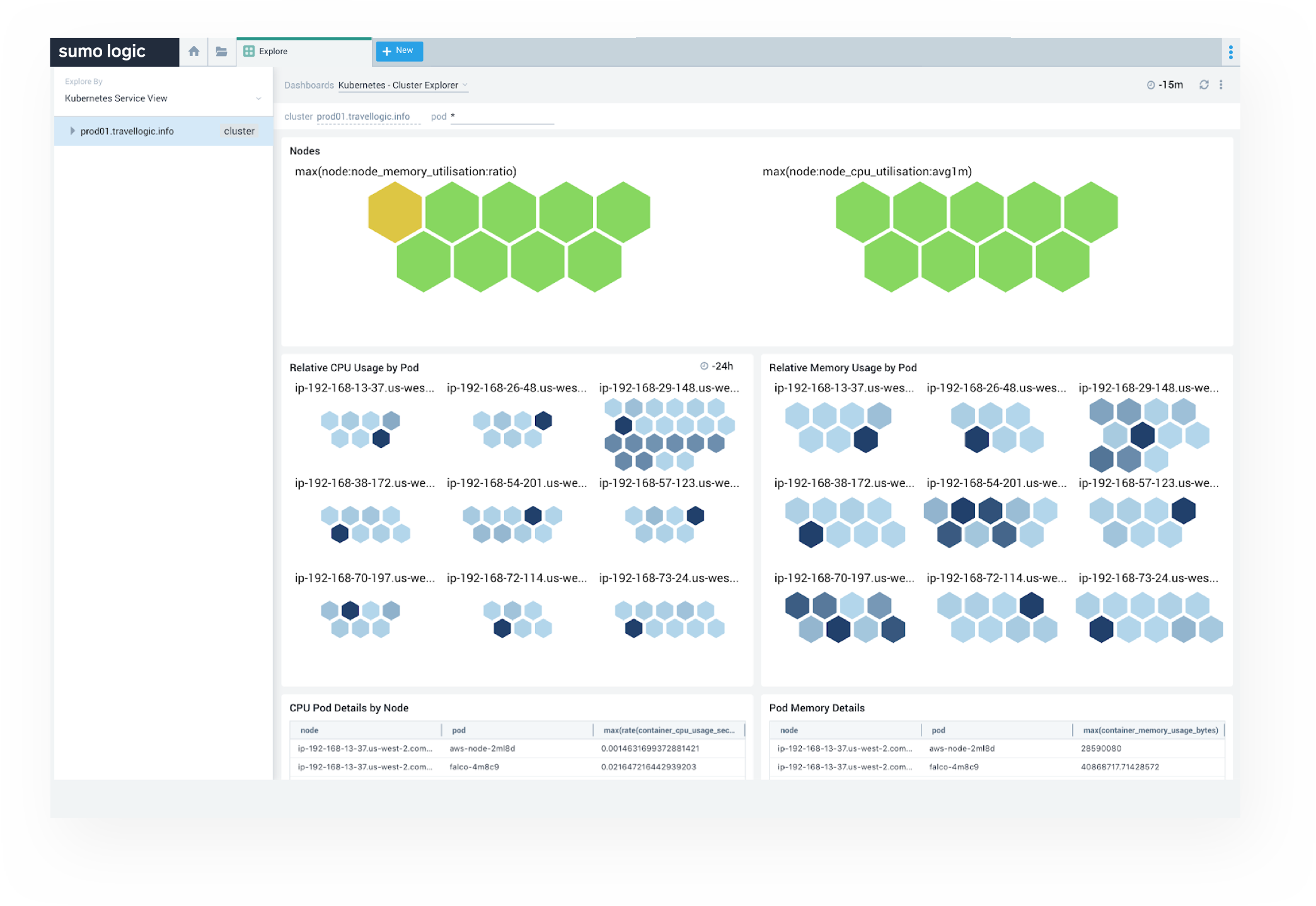
K8s Monitoring Dashboards
Monitor, secure, and optimize your Kubernetes cluster
Try it free for 30 days. No credit card required.
Please enter a valid email address.

Please check your inbox
To start using Sumo Logic, please click the activation link in the email sent from us. We sent an email to:
[email protected]@[email protected]
K8s Monitoring Dashboards
No credit card required. Up and running in minutes.
You're in good company
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.

Logs Metrics Kubernetes