
2022 Gartner® Magic Quadrant™ SIEM
Get the report
MoreTrusted by thousands of customers globally.
Browse our library of ebooks, briefs, reports, case studies, webinars & more.
April 4, 2023

Your Apache HTTP server access and error logs contain a wealth of actionable insights about potential server configuration and web application issues. The problem is that this information is hidden within millions of log messages, so you need analytics to efficiently extract these insights so you can respond to problems before they impact your users.
Apache log analysis revolves around two activities: monitoring and troubleshooting.
First, you need to track key performance indicators in real-time dashboards so you can identify abnormal behavior as it’s happening. Then, when these dashboards indicate that something has gone wrong, you need a powerful query language to dig deeper into relevant log messages to efficiently troubleshoot the issue.
Together, the monitoring and troubleshooting features of an Apache eventlog analyzer results in faster root cause analysis, increased uptime, and fewer headaches.
Apache error log analysis makes it easier to monitor problems in real time and troubleshoot critical issues when they occur. Your Apache error logs contain all the information you need to do these things, but extracting useful insights from millions of log entries can be tricky without a dedicated log management solution.
Depending on your LogLevel directive, Apache error logs contain verbose details about the inner workings of your servers. A good place to start your error log analysis is to strip away this noise by isolating serious errors.
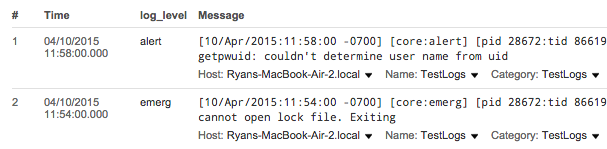
In Sumo Logic, you can extract emergency, alert, and critical-level error log messages with the following query:
_sourceCategory=Apache/Error | parse regex "\[.*:(?<log_level>[a-z]+)\]" | where log_level in ("emerg", "alert", "crit")
Sumo Logic is designed to collect all of your log data, which is why you need to select Apache error logs with the _sourceCategory metadata field. Also note the regular expression that parses the log_level assumes the default Apache 2.4 error log format.

Running this query will list all of the matching error log entries in the Messages tab, as shown above. This gives you a lot of debugging info, but it’s nothing you couldn’t find with a text editor. The real power of Apache log analytics is the ability to aggregate and visualize these error logs.
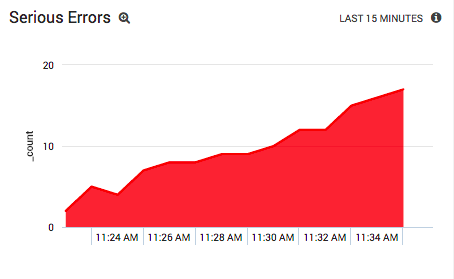
To stay on top of system-critical errors, you can set up a live panel that displays the number of errors in real-time. First, you need to group logs into 5-minute intervals with the timesliceoperator. This lets you count the total logs in each group with the count operator:
_sourceCategory=Apache/Error | parse regex "\[.*:(?<log_level>[a-z]+)\]" | where log_level in ("emerg", "alert", "crit") | timeslice 5m | count by _timeslice
Visualizing the results as an area chart gives you a clear picture of how many errors your Apache system is generating. You can then save this chart as a panel by adding it to a dashboard. With Sumo Logic, you can periodically modify or re-execute the underlying query and update the panel automatically.
This kind of real-time window into your Apache servers is the perfect complement to continuous integration environments. If an update to your web application causes serious problems, this panel will let you know immediately. You can then roll back the update and fix those issues before they affect too many of your visitors.
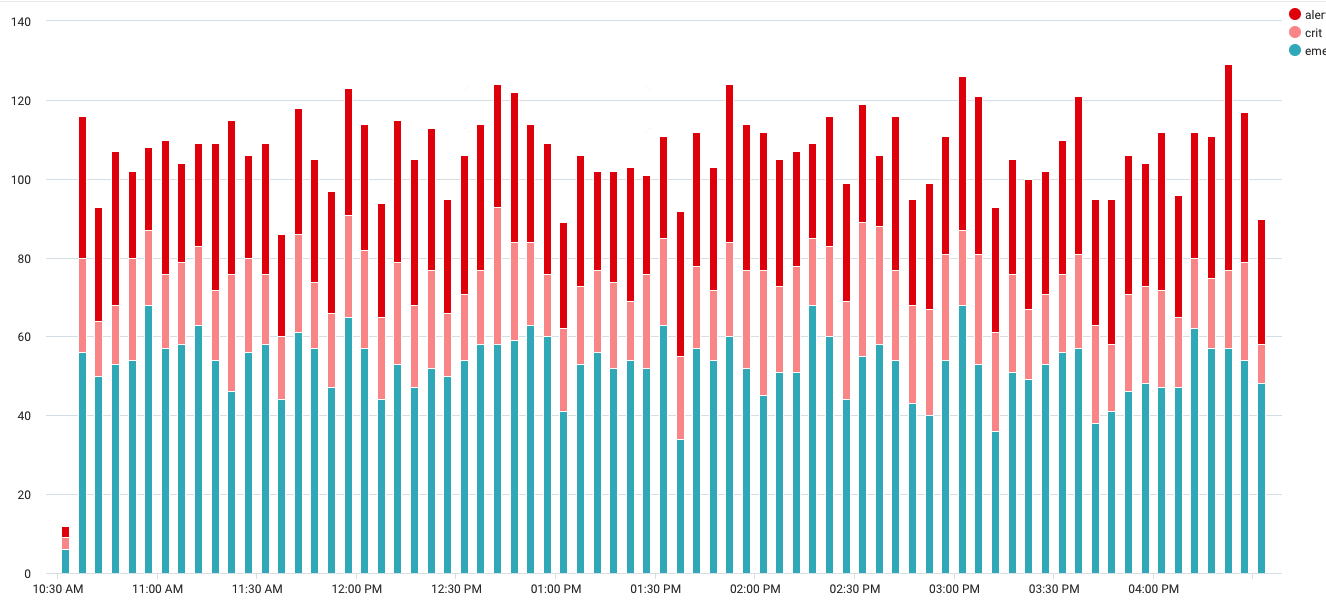
We might also want to count by multiple series over time. To do this we use the timeslice and transpose operators to format the data into a row and column format.
_sourcecategory=Apache/Error | parse regex "\[.*:(?[a-z]+)\]" | where log_level in ("emerg", "alert", "crit") | timeslice 5m | count by _timeslice,log_level | transpose row _timeslice column log_level
Now a chart over time can show multiple dynamically named series based on the value. Here an example that shows a stacked column chart of log levels over time.
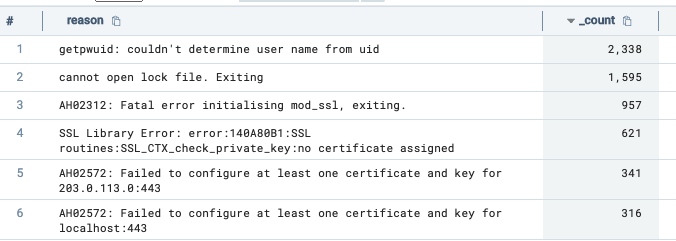
Knowing how many errors are occurring is a great first step towards making sense of your error logs, but it’s also useful to know what kinds of errors are occurring. Using the exact same process, you can create another panel that displays the most common error reasons. First, you need to form a query that extracts the information you're after:
_sourceCategory=Apache/Error | parse regex "\[.*:(?<log_level>\w+)\] .*\] (?<reason>.*)$" | where log_level in ("emerg", "alert", "crit") | count reason | sort _count | limit 10
Then you can save the resulting table as a live panel:
The idea is to build up dashboards that contain all the metrics you’ll need, so when your system has an issue you can quickly switch into troubleshooting mode.
Real-time monitoring lets you know that errors are occurring, but you also need to understand why they’re occurring. After your dashboards tell you that something has gone wrong, the next step is to look for more specific information with custom queries. This is the troubleshooting aspect of Apache logging analytics.
You already know the most common error reasons from your panel in the previous section. Now, it’s time to ask deeper questions like who or what is causing system-critical errors:
_sourceCategory=Apache/Error | parse regex "(?<client_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})" | parse regex "\[.*:(?<log_level>[a-z]+)\]" | where client_ip !="" AND log_level in ("emerg", "alert", "crit") | count client_ip | top 10 client_ip by _count
Any users causing a disproportionate number of errors will be immediately apparent after visualizing the results as a pie chart.
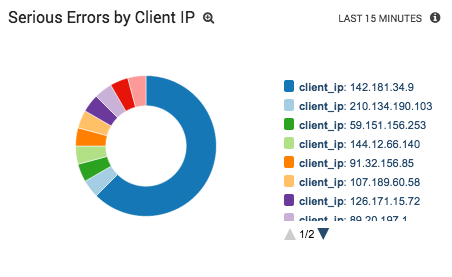
If you do happen to find that a particular user or IP address range is crashing your system, you can block those addresses with a deny from directive in your .htaccess file:
<pre>order allow,denydeny from 142.181.34.9allow from all</pre>
Troubleshooting often involves looking for specific kinds of errors. For example, the data in your panels might suggest that a server is rebooting too often. You can perform a custom query to get a clearer picture of server start and stop events:
_sourceCategory=Apache/Error | parse regex ".*\] (?<reason>.*)$" | if(reason matches "caught SIGTERM, shutting down", 1, 0) as server_stop | if(reason matches "*-- resuming normal operations", 1, 0) as server_start | timeslice by 5m | sum(server_stop) as server_stops, sum(server_start) as server_starts by _timeslice
This inspects each log entry and looks for the specific messages that Apache generates every time it starts or stops. Any abnormal behavior is easy to see after graphing the results as a stacked column chart.
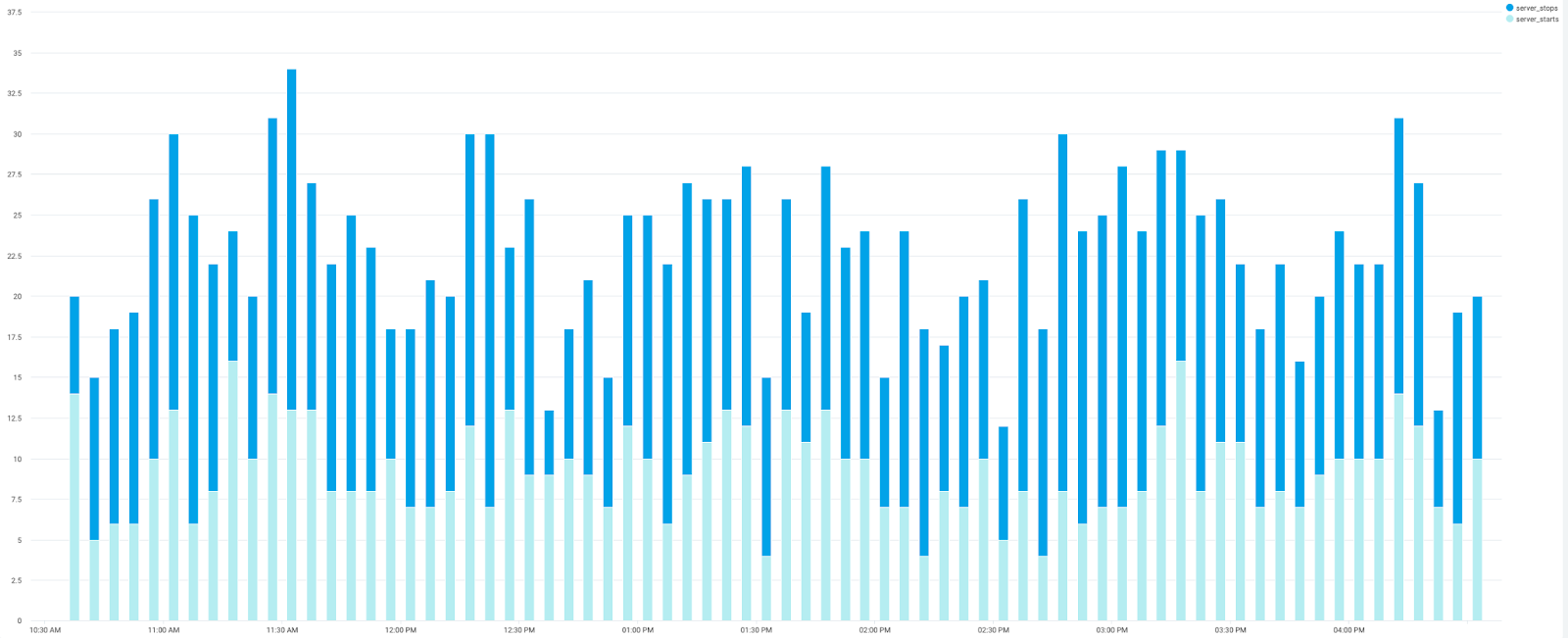
But, this is only the beginning of the troubleshooting process. To find the root cause of the restart events, you’ll need to perform more custom queries around the time frames indicated by the above results.
The actual queries involved in Apache log analytics aren’t generally all that complicated. The hard part is figuring out which questions to ask and how to find the answer in your log data. As you saw in this section, effective analysis requires intimate knowledge of the Apache log file messages produced by your Apache httpd server.
A good way to approach error log analysis is peacetime preparation followed by wartime troubleshooting. During peacetime, you’re getting ready for when things go wrong by configuring panels that contain all the metrics you’re interested in. During wartime, these panels guide your troubleshooting efforts and help you write custom queries that identify the root cause of the problem.
Unlike system-critical errors, Apache 400- and 500-level status codes usually relate more to content and linking issues rather than problems with your Apache configuration file. In this section, you learn how a dedicated Apache access log analyzer can make it much easier to monitor and troubleshoot status code errors.
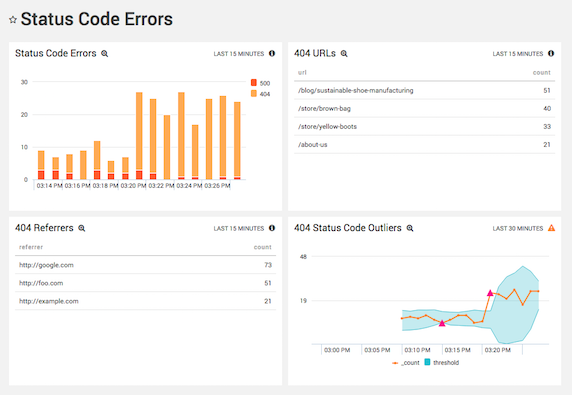
To isolate access logs that contain 400- and 500-level status codes, you need to extract the status code from each log using the parse operator. Then, it’s easy to constrain the query to find status code errors with a where clause:
_sourceCategory=Apache/Access | parse "HTTP/1.1\" * " as status_code | where num(status_code) >= 400
_sourceCategory is a metadata field that Sumo Logic attaches to each log message as it’s collected, and Apache/Access is the canonical label for an Apache access log file. If you used a different value when setting up your source, be sure to change your query accordingly.
Even for moderately busy websites, Apache servers produce millions of access logs. The first step towards identifying useful trends in all this data is to get rid of logs that you're not interested in. This allows you to perform calculations with relevant log entries and visualize the results. In turn, this makes it much easier to monitor potential problems than sifting through Apache logs with grep.
For example, you can graph your status code errors over time with the following query:
_sourceCategory=Apache/Access | parse "HTTP/1.1\" * " as status_code | where num(status_code) >= 400 | timeslice 5m | count as count by _timeslice, status_code | transpose row _timeslice column status_code
After adding the timeslice and count operators, Sumo Logic automatically enables its graphing capabilities. All it takes is a few clicks to display these results as a stacked column chart. This gives you an at-a-glance view of every status code error in your Apache system.
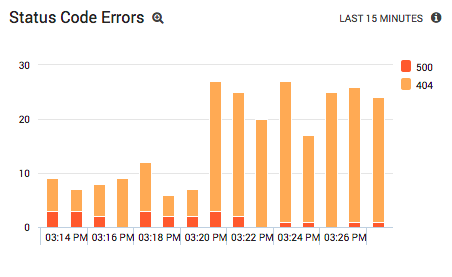
Sumo Logic's monitoring capabilities give you live dashboards, consisting of multiple panels that track different key performance indicators (KPIs) in real time. The idea is to save your chart as a panel so you always have a transparent window into your Apache web server’s operations.
You now have a lot of status code information at your fingertips. If a PHP script starts to hang, you will see a spike in 500 errors. If a referring site contains broken links, you will see 404 errors go up. Even obscure errors like 503s caused by an overloaded server will be readily apparent.
Configuring live dashboards is all about preparing for when your server breaks. To this end, you should probably include another panel that displays which URLs are generating 404 errors.
_sourceCategory=Apache/Access | parse regex "[A-Z]+ (?<url>.+) HTTP/1\.1\" (?<status_code>\d+) " | where num(status_code)=404 | count as count by url | sort count | limit 10
Just like your other panel, you can save this query in a dashboard so the information is readily accessible.
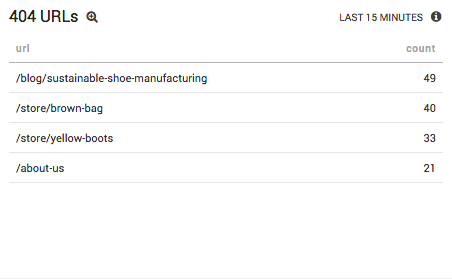
Of course, you’ll likely have more sophisticated dashboards set up for production monitoring, but even these two panels give you a realistic glimpse into the utility of Apache error log analytics. A common scenario might be:
You see that 404s are spiking in our first panel.
So, you look at our second panel to see which URLs are causing 404s.
It turns out one particular URL is causing most of them, which means that it’s time to dig deeper to find the root cause of the 404s.
This is where you switch into troubleshooting mode and start running custom queries that investigate the data in your pre-configured panels.
Odds are, these 404 errors are coming from a broken link. To figure out where this broken link is, you need to find all the referrers that are pointing people to the missing page. If the URL is /about-us, the following query will do just that:
_sourceCategory=Apache/Access | parse regex "[A-Z]+ (?<url>.+) HTTP/1\.1\" (?<status_code>\d+)\s\S+\s\"(?<referrer>\S+)\"" | where num(status_code)=404 | where url matches "*about-us*" | count as count by referrer | sort count | limit 10
The matches operator recognizes asterisk wildcards, making it easier to search for slugs in a URL. This query then tallies up how many times each referrer sent someone to the missing resource.
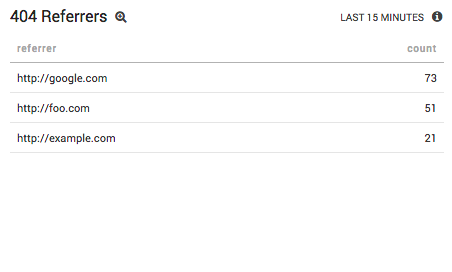
If you find external websites in this list, it probably means you changed a URL and forgot to add a redirect. Alternatively, you may find pages from your own site in the results, which could indicate broken internal links or missing media resources.
This query is also a good demonstration of the separation of concerns involved in Apache log analytics: monitoring vs. troubleshooting. You wouldn’t want to save this query as a live panel, because it’s much too specific to be of use as a monitoring metric.
A certain amount of status code errors are expected based on your traffic volume. It’s important to keep this in mind when searching for atypical behavior because it means you need to replace questions like “Have there been more than a hundred 404 errors?” with “Have 404 errors fallen outside the expected range?”
One way to represent that “expected range” is as a multiple of the standard deviation around a rolling average. This is precisely what the outlier operator was designed to do:
_sourceCategory=Apache/Access | parse "HTTP/1.1\" * " as status_code | where num(status_code)=404 | timeslice 5m | count _timeslice | outlier _count window=6, threshold=2.5
This calculates the moving average of 404 errors using 6 data points, then detects when the number of 404 errors is beyond 2.5 standard deviations of that average. Graphing the results as a line chart shows both the range and any outliers that were detected:
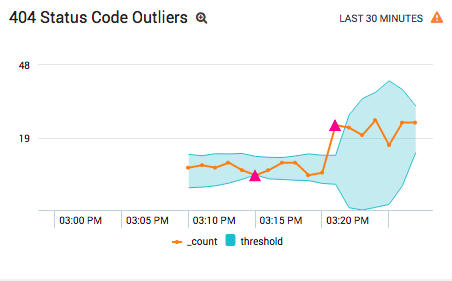
The outlier operator can be useful in both panels or troubleshooting queries, but it really shines when used in real-time alerts (requires Sumo Logic Professional). It avoids setting static thresholds for the alerts, which often results in false-positives when your traffic is volatile or cyclical.
While most status code errors are relatively straightforward to fix, identifying them with real-time visualizations is much more reliable and convenient than manually clicking through every link in your site or inspecting the raw text of your Apache log files.
You’re not just watching 500 errors occur; you’re figuring out why they’re occurring with troubleshooting queries, getting your developers to implement a solution, and verifying that solution worked back in your live dashboards.
As a data structure, Apache logs are pretty simple. As you add more servers for load balancing, high-availability or new development environments, making sense of your log files becomes increasingly difficult. When you have a hundred servers generating millions of log messages, getting to the root cause of an issue is time-consuming and error prone.
What is needed is a dedicated Apache log analyzer tool to centralize your logs, monitor errors and provide the ability to troubleshoot issues as they occur in real time.
Sumo Logic has built an integration to specifically analyze and visualize errors logged by Apache servers. This integration collects logs and metrics (using Telegraf agent) and combines these into a single unified view. With the Integration for Apache, you can:
Monitor 404 errors
Identify 404 URLs and referrers
Set dynamic thresholds to alert on “abnormal” levels of 500- errors
Optimize web resources
Identify misbehaving bots
Speed up Apache response times
Get started quickly with key alerting use cases using pre-built monitors
Apache log analytics doesn’t exist in isolation. A tool like Sumo Logic is meant to integrate tightly with the rest of your web development workflow. You’re not just watching 500 errors occur; you’re figuring out why they’re occurring with troubleshooting queries, getting your developers to implement a solution, and verifying that it worked back in your live dashboards.
Learn more about log management best practices.
Reduce downtime and move from reactive to proactive monitoring.
Build, run, and secure modern applications and cloud infrastructures.
Start free trial
No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.
