
2022 Gartner® Magic Quadrant™ SIEM
Get the report
MoreTrusted by thousands of customers globally.
Browse our library of ebooks, briefs, reports, case studies, webinars & more.
January 14, 2021
One of Amazon Web Services’ (AWS) most well-known services is AWS DynamoDB. Some of AWS’s most notable customers use DynamoDB for their database needs – companies such as Netflix, The Pokemon Company, and Snapchat.
DynamoDB is relatively simple to set up and configure, and it integrates well with many web-based applications. DynamoDB supports technology solutions in gaming, retail, bank and finance, and the software industry.
This article will investigate what makes DynamoDB a great choice as the database to back your web applications. We’re also going to talk about some best practices and why DynamoDB might not be the best solution for your data storage needs. Finally, we’ll talk about what you need to do to get the most performance out of DynamoDB, and how you can leverage the DynamoDB experience from Sumo Logic to monitor and ensure you’re getting the best possible performance from DynamoDB.
DynamoDB is part of a group of databases, known as a NoSQL or non-relational databases. Unlike databases like MySQL and Oracle, which rely on a well-defined table schema and relationships between tables, NoSQL databases are document-based. Each document within a table requires a primary key and may have additional indexes if required. You can work with DynamoDB as you would other NoSQL databases like MongoDB, Cassandra, and Couchbase.
An advantage of DynamoDB over other NoSQL databases is that it is hosted and managed by AWS. The user does not need to provision the underlying hardware or concern themselves with adding additional capacity as the database’s storage needs increase. DynamoDB offers high-availability, fault-tolerance and can be accessed from around the globe as needed.
DynamoDB pricing is based on the numbers of reads and writes performed on the database per second, also known as IOPS. Users can choose between an on-demand capacity (which works well for unpredictable traffic patterns) and provisioned capacity (which suits more uniform and predictable traffic patterns). DynamoDB can be scaled as needed by your applications, and integrates seamlessly with other services within the AWS ecosystem, and even applications outside of AWS if required.
DynamoDB interactions occur through a well-defined API, similar to other AWS-managed services. Access to the API is managed and controlled with AWS Identity and Access Management. IAM permissions grant you fine-grained control over who and which machines are allowed to interact with the database, and what operations each is permitted to do.
AWS also provides SDKs for Java, Javascript, Python, .NET, Ruby, and other popular languages. The SDKs provide a well-tested library of native functions that authenticate and manage interactions with the database. The Java code snippet below shows a simple read operation from a table containing information on books. The code demonstrates creating a connection, forming the query in the form of a key, and the request. You can find more examples and tutorials in the DynamoDB Developer Guide.
public BookInfo getBookInfo(String author, String title) {
AmazonDynamoDB client = AmazonDynamoDBClientBuilder.standard().build();
HashMap<String, AttributeValue> key = new HashMap<String, AttributeValue>();
key.put("Author", new AttributeValue().withS(author));
key.put("Title", new AttributeValue().withS(title));
DynamoDB dynamoDB = new DynamoDB(client);
GetItemRequest request = new GetItemRequest()
.withTableName("Books")
.withKey(key);
try {
GetItemResult result = client.getItem(request);
if (result && result.getItem() != null) {
return BookUtils.ParseBook(result.getItem);
}
return BookUtils.BookNotFoundResult(author, title);
} catch (Exception e) {
System.err.println("Unable to retrieve data: ");
}
}
Fig. 2 Java Function to Retrieve Book Information from a Table
We’ve already discussed many of the advantages of using DynamoDB. Ease of use, no need to manage infrastructure, and the ease of scaling up as your needs increase. You can create new DynamoDB tables in code, from the AWS CLI or through the AWS Console. Newly created tables are available in minutes and give you single-digit millisecond performance.
As your dataset grows, AWS automatically provisions additional partitions or shards and spreads your provisioned IOPS evenly across all partitions. This approach ensures that your capacity and the underlying infrastructure grow with your needs. Given the advantages we’ve discussed thus far, DynamoDB might be the database for you. There are some aspects of DynamoDB that you need to consider before adopting it wholeheartedly.
One problem that DynamoDB users may encounter is having their requests throttled if they exceed the allotted capacity. This may seem like an easy situation to manage, but there are some unique situations that may exacerbate the problem.
One of these problematic situations involves Hot Keys or Hot Partitions. DynamoDB uses the primary key, which is a single value, or a composition of several values to distribute the documents between all partitions. If your keys are generated randomly using a UUID, or something similar, the documents will be distributed evenly. If your keys aren’t random, you might end up with a disproportionate distribution of documents. When one partition has a higher percentage of documents, it will receive a higher number of requests to read and write. As IOPS are distributed evenly between the partitions, you might end up being throttled, despite having provisioned enough operational capacity.
Related to the Hot Key problem, is that of rapid growth. DynamoDB partitions have a maximum size of 10GB, and as the dataset grows, additional partitions will be added. Adding additional partitions reduces the capacity on each partition which may also cause throttling problems, requiring you to increase your IOPS provisioning, and thus your costs. If your dataset is growing rapidly, your costs to manage that data will grow rapidly as well.
While AWS infrastructure does much of the heavy lifting to support DynamoDB, you need to be vigilant about how you’re using the service to ensure optimal performance. Monitoring your tables is essential to ensure you’re controlling your DynamoDB budget and that the applications and services that use the table can perform operations efficiently. Some key areas that you need to be aware of are:
You can monitor these errors using AWS Cloudwatch and set up alarms to alert you when your table or its indexes breach critical thresholds. However, as a generic monitoring solution, Cloudwatch does not offer in-depth analytics and intelligent monitoring that you can otherwise get by partnering with a provider like Sumo Logic.
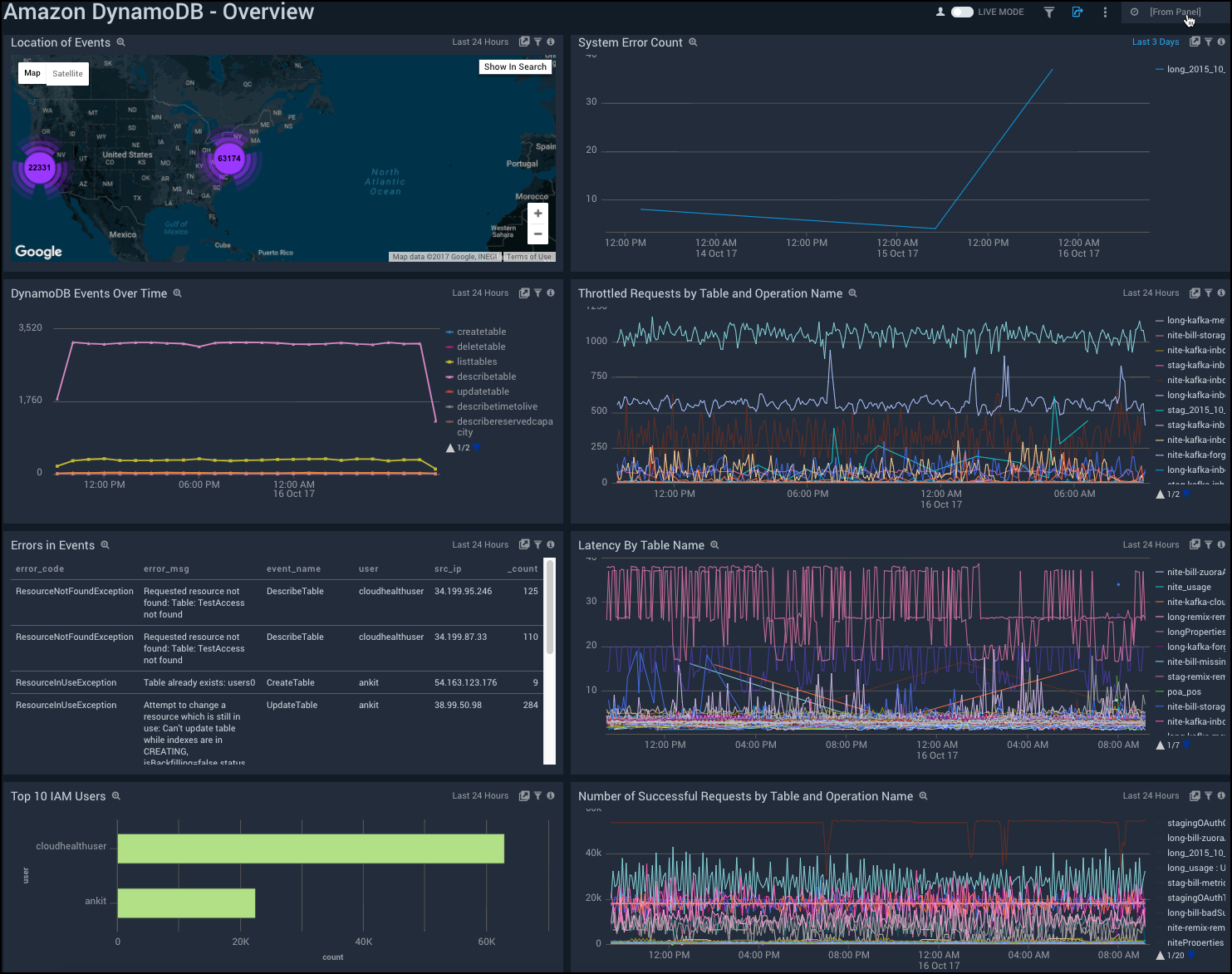
The DynamoDB App from Sumo Logic collects data from Cloudwatch and AWS CloudTrail. It uses this data to generate a dashboard that shows you a comprehensive view of the health and performance of your DynamoDB tables. Thorough and detailed monitoring finds correlations between problems and configurations. Intelligent alerting can identify outliers in the metrics, warn you about malicious activity, and ensure you get the most out of your DynamoDB investment. You can find out more about the Sumo Logic DynamoDB App here, and sign up for a free trial to experience it yourself.
Reduce downtime and move from reactive to proactive monitoring.
Build, run, and secure modern applications and cloud infrastructures.
Start free trial
Mike Mackrory is a Global citizen who has settled down in the Pacific Northwest — for now. By day he works as a Lead Engineer on a DevOps team, and by night, he writes and tinkers with other technology projects. When he's not tapping on the keys, he can be found hiking, fishing and exploring both the urban and rural landscape with his kids. Always happy to help out another developer, he has a definite preference for helping those who bring gifts of gourmet donuts, craft beer and/or single-malt Scotch.
More posts by Mike Mackrory.

No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.
