
2022 Gartner® Magic Quadrant™ SIEM
Get the report
MoreTrusted by thousands of customers globally.
Browse our library of ebooks, briefs, reports, case studies, webinars & more.
June 12, 2018
I like to think about Kubernetes like a vehicle. You can use a vehicle to get you to places you want to go, and Kubernetes helps you get to places where you have better control of your containers. Just like a car, k8s consists of multiple layers of components working together to get you to those places.
Let’s dive into some of those individual components, or “car parts” if you will…
[Learn More: Full Stack Kubernetes and Docker Monitoring]
Kubernetes provides multiple abstractions that play an integral role in the orchestration of your containers. These abstractions are like the various components of a car that you use when driving such as the radio, the speedometer or the gas pedal.
[Learn More: Continuous Intelligence Kubernetes]
At an infrastructure level, a Kubernetes cluster is made up of two types of components: the Master, and the Nodes. These may be virtual or physical machines as Kubernetes can run anywhere. The Master is the brains of the operation, overseeing the Nodes which are the collective resources the Master can use to run your containers. Think of the entire vehicle as a Kubernetes cluster. The Master is like the engine that powers the vehicle, and the wheels are like the Nodes that allow the engine to push it forward.
Like the tires of a vehicle are made up of multiple parts, so are the Nodes of a Kubernetes cluster. These components work together to provide the Kubernetes Control Plane with a resource it can use to schedule your containers.
The Master runs all the components that make up the Kubernetes Control Plane. The Control Plane components work together to orchestrate your containers. In the same way that an engine has a lot of pieces that work together to power your vehicle, the Kubernetes Control Plane is no different. Each piece is responsible for a specific area that powers k8s.
Putting these pieces together, we can start to see the architecture of Kubernetes:
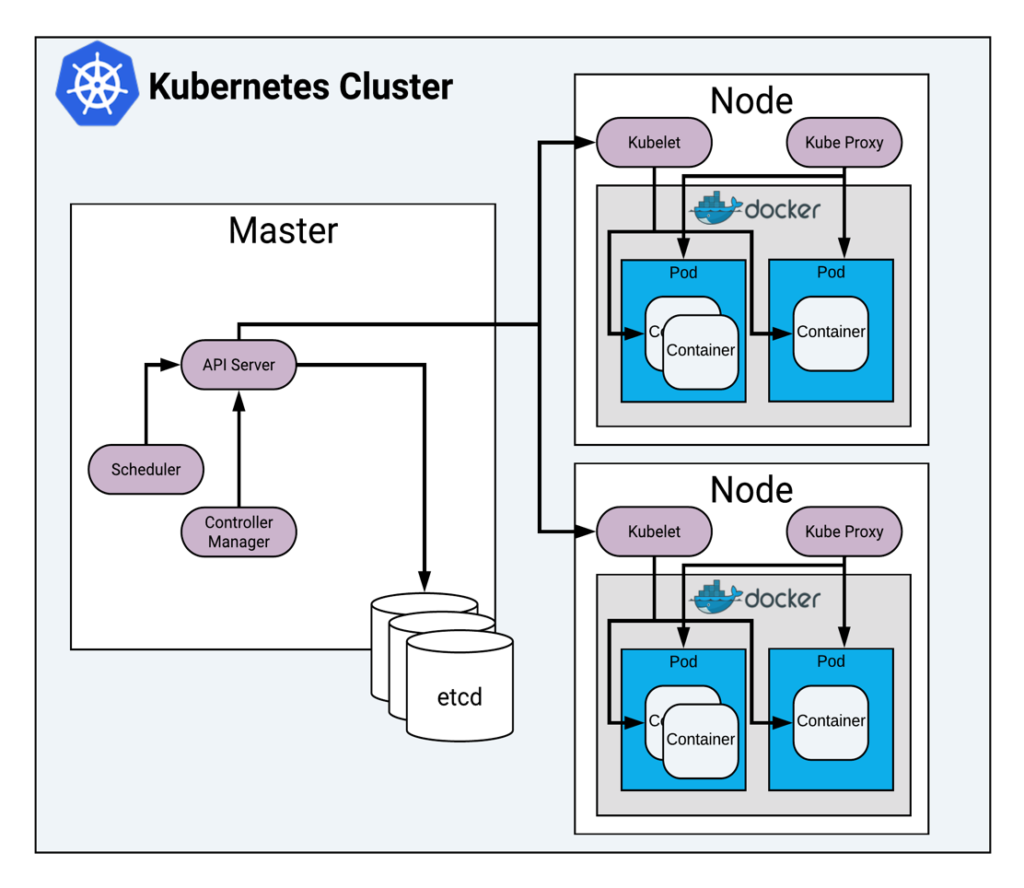
Now that we know what’s under the hood of Kubernetes, we can see it is a complex machine with a lot of components operating together. This machine gives you the ability to manage, deploy and scale your containerized applications with ease. You might even be using a managed service such as Amazon EKS or Google GKE to provide you a highly available, secure, and managed control plane, letting you focus on your containerized applications. In both of these scenarios, the ability to monitor and troubleshoot your applications — and potentially the Kubernetes Control Plane — is critical to delivering reliable, fault-tolerant distributed applications running in containers.
[Learn More: Kubernetes Dashboard]
So how do we monitor all of these pieces? In our next post in this series, we are going to go through each component and identify what is critical to monitor, and how you can use Sumo Logic’s machine data analytics platform to stay on top of what’s happening in your Kubernetes clusters.
When monitoring any application, you always need to be able to answer two critical questions: What is happening? Why is this happening? Access to machine data from your applications to address these questions ensures that you can quickly identify issues and take action to remedy. This machine data comes in two forms, metrics and logs.
Time series metrics tell you what is happening, for example how much load is on the system or what current resource consumption is. Metrics are like the various indicators in your car similar to the check engine light that goes on when there is a problem. They provide you insight into the current state of behavior and can be a warning sign of issues to come.
Logs tell you why something is happening. They provide a record of the events that are occurring in your application. They can be informative, providing context around the actions the app is taking, or they can be errors indicating why something is breaking. Logs are like the results of the diagnostic tool your mechanic plugs in to determine why the check engine light is on.
Learn how to monitor, troubleshoot, and secure your Kubernetes environment with Sumo Logic.
Like any application, Kubernetes has a comprehensive set of machine data to enable you always answer the what and why when it comes to monitoring it. You also need machine data for the applications running inside of Kubernetes. Let’s dive into the critical data you need to collect from every Kubernetes cluster.
Kubernetes is written in GoLang and reveals some essential metrics about the GoLang runtime. These metrics are necessary to keep an eye on the state of what is happening in your GoLang processes. There are also critical metrics related to etcd. Multiple components interact with etcd and keeping an eye on those interactions gives you insights into potential etcd issues. Below are some of the top GoLang stats and common etcd metrics to collect that are exposed by most Kubernetes components.
[Learn More: Advanced Metrics with Kubernetes]
| Metric | Components | Description |
| go_gc_duration_seconds | All | A summary of the GC invocation durations. |
| go_threads | All | Number of OS threads created. |
| go_goroutines | All | Number of goroutines that currently exist. |
| etcd_helper_cache_hit_count | API Server, Controller Manager | Counter of etcd helper cache hits. |
| etcd_helper_cache_miss_count | API Server, Controller Manager | Counter of etcd helper cache miss. |
| etcd_request_cache_add_latencies_summary | API Server, Controller Manager | Latency in microseconds of adding an object to etcd cache. |
| etcd_request_cache_get_latencies_summary | API Server, Controller Manager | Latency in microseconds of getting an object from etcd cache. |
| etcd_request_latencies_summary | API Server, Controller Manager | Etcd request latency summary in microseconds for each operation and object type. |
As we learned, the Kubernete Control Plane is the engine that powers Kubernetes. It consists of multiple parts working together to orchestrate your containerized applications. Each piece serves a specific function and exposes its own set of metrics to monitor the health of that component. To effectively monitor the Control Plane, visibility into each components health and state is critical.
The API Server provides the front-end for the Kubernetes cluster and is the central point that all components interact. The following table presents the top metrics you need to have clear visibility into the state of the API Server.
| Metric | Description |
| apiserver_request_count | Count of apiserver requests broken out for each verb, API resource, client, and HTTP response contentType and code. |
| apiserver_request_latencies | Response latency distribution in microseconds for each verb, resource and subresource. |
Etcd is the backend for Kubernetes. It is a consistent and highly-available key-value store where all Kubernetes cluster data resides. All the data representing the state of the Kubernetes cluster resides in Etcd. The following are some of the top metrics to watch in Etcd.
| Metric | Description |
| etcd_server_has_leader | 1 if a leader exists, 0 if not. |
| etcd_server_leader_changes_seen_total | Number of leader changes. |
| etcd_server_proposals_applied_total | Number of proposals that have been applied. |
| etcd_server_proposals_committed_total | Number of proposals that have been committed. |
| etcd_server_proposals_pending | Number of proposals that are pending. |
| etcd_server_proposals_failed_total | Number of proposals that have failed. |
| etcd_debugging_mvcc_db_total_size_in_bytes | Actual size of database usage after a history compaction. |
| etcd_disk_backend_commit_duration_seconds | Latency distributions of commit called by the backend. |
| etcd_disk_wal_fsync_duration_seconds | Latency distributions of fsync calle by wal. |
| etcd_network_client_grpc_received_bytes_total | Total number of bytes received by gRPC clients. |
| etcd_network_client_grpc_sent_bytes_total | Total number of bytes sent by gRPC clients. |
| grpc_server_started_total | Total number of gRPC’s started on the server. |
| grpc_server_handled_total | Total number of gRPC’s handled on the server. |
Scheduler watches the Kubernetes API for newly created pods and determines which node should run those pods. It makes this decision based on the data it has available including the collective resource availability as well as the resource requirements of the pod. Monitoring scheduling latency ensures you have visibility into any delays the Scheduler is facing.
| Metric | Description |
| scheduler_e2e_scheduling_latency_microseconds | The end-to-end scheduling latency, which is the sum of the scheduling algorithm latency and the binding latency. |
Controller Manager is a daemon which embeds all the various control loops that run to ensure the desired state of your cluster is met. It watches the API server and takes action depending on the current state versus the desired state. It’s important to keep an eye on the requests it is making to your Cloud provider to ensure the controller manager can successfully orchestrate. Currently, these metrics are available for AWS, GCE, and OpenStack.
| Metric | Description |
| cloudprovider_*_api_request_duration_seconds | The latency of the cloud provider API call. |
| cloudprovider_*_api_request_errors | Cloud provider API request errors. |
Kube-State-Metrics is a Kubernetes add-on that provides insights into the state of Kubernetes. It watches the Kubernetes API and generates various metrics, so you know what is currently running. Metrics are generated for just about every Kubernetes resource including pods, deployments, daemonsets, and nodes. Numerous metrics are available, capturing various information and below are some of the key ones.
| Metric | Description |
| kube_pod_status_phase | The current phase of the pod. |
| kube_pod_container_resource_limits_cpu_cores | Limit on CPU cores that can be used by the container. |
| kube_pod_container_resource_limits_memory_bytes | Limit on the amount of memory that can be used by the container. |
| kube_pod_container_resource_requests_cpu_cores | The number of requested cores by a container. |
| kube_pod_container_resource_requests_memory_bytes | The number of requested memory bytes by a container. |
| kube_pod_container_status_ready | Will be 1 if the container is ready, and 0 if it is in a not ready state. |
| kube_pod_container_status_restarts_total | Total number of restarts of the container. |
| kube_pod_container_status_terminated_reason | The reason that the container is in a terminated state. |
| kube_pod_container_status_waiting | The reason that the container is in a waiting state. |
| kube_daemonset_status_desired_number_scheduled | The number of nodes that should be running the pod. |
| kube_daemonset_status_number_unavailable | The number of nodes that should be running the pod, but are not able to. |
| kube_deployment_spec_replicas | The number of desired pod replicas for the Deployment. |
| kube_deployment_status_replicas_unavailable | The number of unavailable replicas per Deployment. |
| kube_node_spec_unschedulable | Whether a node can schedule new pods or not. |
| kube_node_status_capacity_cpu_cores | The total CPU resources available on the node. |
| kube_node_status_capacity_memory_bytes | The total memory resources available on the node |
| kube_node_status_capacity_pods | The number of pods the node can schedule. |
| kube_node_status_condition | The current status of the node. |
As we learned in Part 1 of our journey into Kubernetes, the Nodes of a Kubernetes cluster are made up of multiple parts, and as such you have numerous pieces to monitor.
Keeping a close eye on Kubelet ensures that the Control Plane can always communicate with the node that Kubelet is running on. In addition to the common GoLang runtime metrics, Kubelet exposes some internals about its actions that are good to track.
| Metric | Description |
| kubelet_running_container_count | The number of containers that are currently running. |
| kubelet_runtime_operations | The cumulative number of runtime operations available by the different operation types. |
| kubelet_runtime_operations_latency_microseconds | The latency of each operation by type in microseconds. |
Visibility into the standard host metrics of a node ensures you can monitor the health of each node in your cluster, avoiding any downtime as a result of an issue with a particular node. You need visibility into all aspects of the node, including CPU and Memory consumption, System Load, filesystem activity and network activity.
Monitoring of all of the Kubernetes metrics is just one piece of the puzzle. It is imperative that you also have visibility into your containerized applications that Kubernetes is orchestrating. At a minimum, you need access to the resource consumption of those containers. Kubelet access the container metrics from CAdvisor, a tool that can analyze resource usage of containers and makes them available. These include the standard resource metrics like CPU, Memory, File System and Network usage.
As we can see, there are many vital metrics inside your Kubernetes cluster. These metrics ensure you can always answer what is happening not only in Kubernetes and the components of it, but also your applications running inside of it.
[Watch: Advanced Kubernetes Metrics]
Logs are how we can answer why something is happening. They provide information regarding what the code is doing and the actions it is taking. Kubernetes delivers a wealth of logging for each of its components giving you insights into the decisions it is making. All of your containerized workloads are also generating logs, providing information into the decisions the code is making and actions it is taking. Access to these logs ensures you have comprehensive visibility to monitor and troubleshoot your applications.
Now that we understand what machine data is available to us, how do we get to this data? The good news is that Kubernetes makes most of this data readily available, you just need the right tool to gather and view it.
As containers are running inside of Kubernetes, the logs files are written to the Node that the container is running on. Every node in your cluster will have the logs from every container that runs on that node. We developed an open-source FluentD plugin that runs on every node in your cluster as a Daemonset. The plugin is responsible for reading the logs and securely sending them to Sumo Logic. It also enriches the logs with valuable metadata from Kubernetes.
When you create objects in Kubernetes, you can assign custom key-value pairs to each of those objects, called labels. These labels can help you organize and track additional information about each object. For example, you might have a label that represents the application name, the environment the pod is running in or perhaps what team owns this resource. These labels are entirely flexible and can be defined as you need. Our FluentD plugin ensures those labels get captured along with the logs giving you continuity between the resources you have created and the log files they are producing.
The plugin can be used on any Kubernetes cluster, whether using a managed service like Amazon EKS or a cluster you are running entirely on your own. It works as simple as deploying a Daemonset to Kubernetes. We provide default configuration that can work out-of-box with nearly any Kubernetes cluster and a rich set of configuration options so you can fine tune it to your needs.
Every component of Kubernetes exposes its metrics in a Prometheus format. The running processes behind those components serve up the metrics on an HTTP URL that you can access. For example, the Kubernetes API Server serves it metrics on https://$API_HOST:443/metrics. You simply need to scrape these various URLs to obtain the metrics.
We developed a new tool specifically designed to ingest Prometheus formatted metrics into Sumo Logic. This tool can run standalone as a script on some box or can run as a container. It can ingest data from any target that provides Prometheus formatted metrics, including those from Kubernetes. And today, we are open-sourcing that tool for all of our customers to use to start ingesting Prometheus formatted metrics.
The Sumo Logic Prometheus Scraper can be configured to point to multiple targets serving up Prometheus metrics. It supports the ability to include or exclude metrics and provides you full control to the metadata that you send to Sumo Logic. The ability to include metadata ensures that when it comes to Kubernetes, you can capture the same valuable metadata that you have in logs in the metrics. You can use this metadata when searching thru your logs and your metrics, and use them together to have a unified experience when navigating your machine data.
Kubernetes is complex. It consists of multiple components working together to orchestrate your containerized applications seamlessly. However, it’s not always smooth sailing with Kubernetes. Let’s talk about a story of a Kubernetes Platform Engineer trying to diagnose an issue with their application:
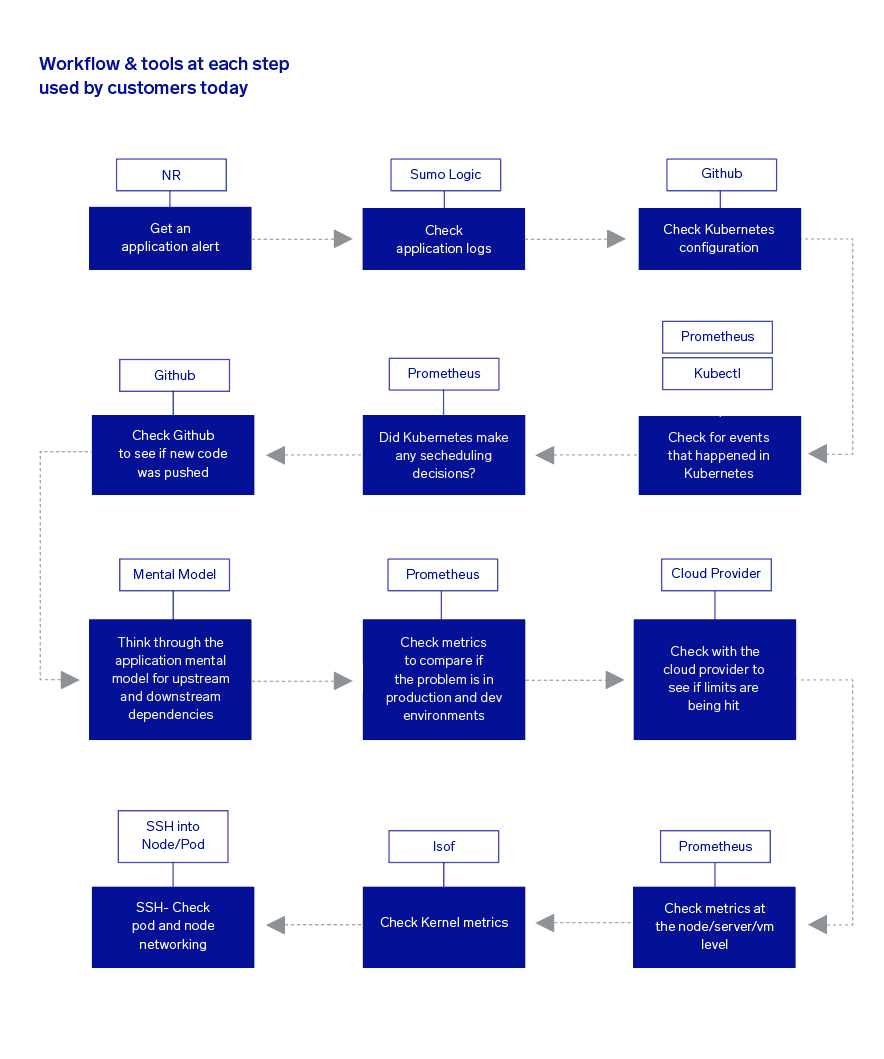
This story is a story we hear over and over again from our customers. When things go wrong in Kubernetes, you have to navigate a complex web dependencies, from Kubernetes to the underlying infrastructure to the application layer.
In order to have observability of a modern application like Kubernetes, you need a Continuous Intelligence platform that gives you discoverability, observability and security of your Kubernetes clusters. I am excited to announce the release of our new solution for Kubernetes. Let’s walk through some of these new capabilities.
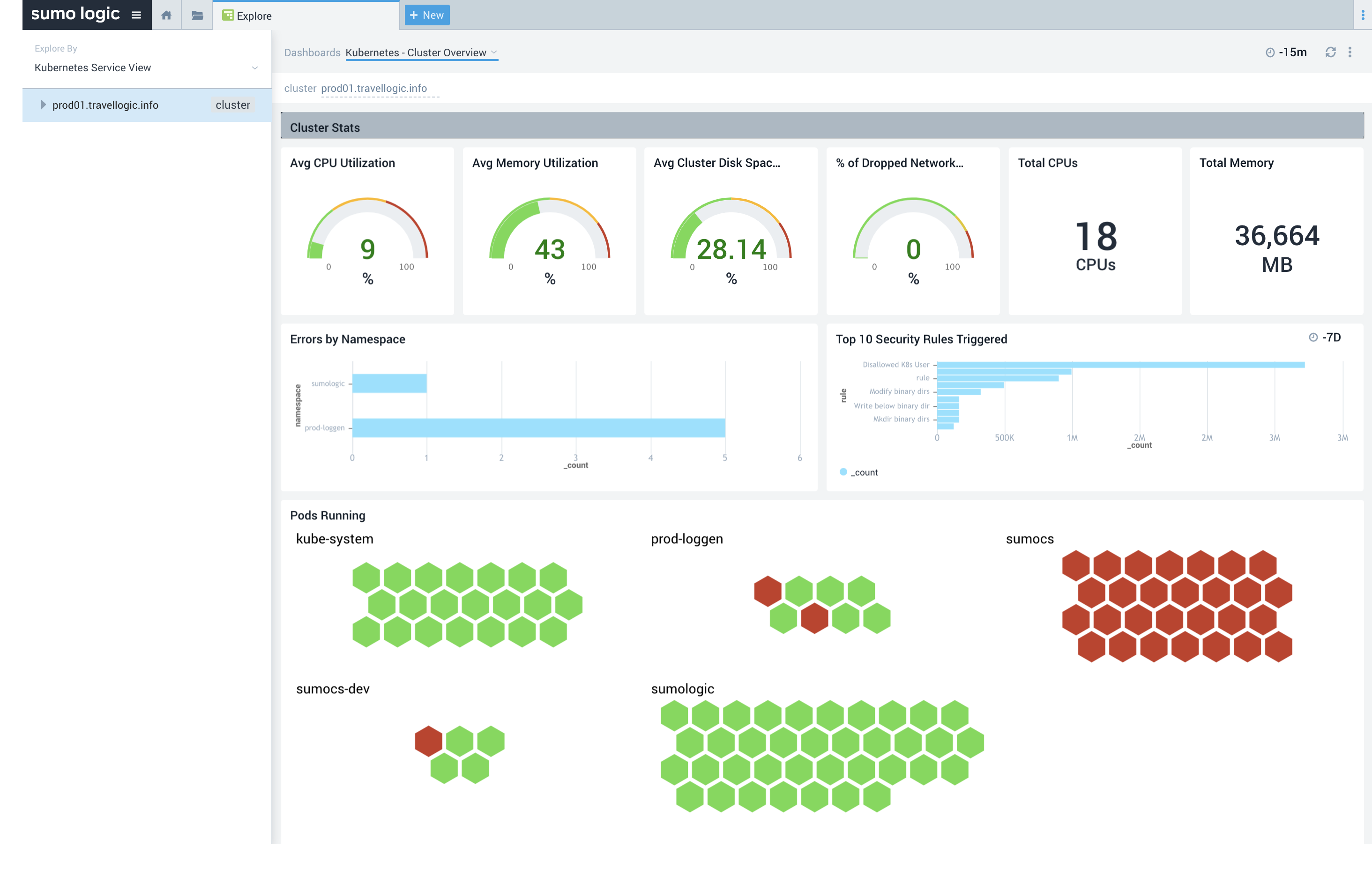
Explore is a single pane of glass that lets you discover your Kubernetes clusters no matter where they are running. Explore is an out of the box, context rich experience that allows our customers to map their Kubernetes objects into Sumo Logic and get immediate rich visibility about the behavior of those objects. This allows customers to perform troubleshooting tasks with less friction. Explore comes with a curated set of views that organize a customer’s metadata, so that they can drill down into their services and applications or into their infrastructure.
Sumo Logic’s new dashboarding framework is optimized for data dense, interactive visualizations for a unified metrics and logs experience. From extensible variables to brand new visualizations like honeycombs, the new dashboard framework lays the foundation for expressive observability across data streams. Our unified logs and metrics panel builders allow you to layer logs and metrics data on the same panels and make it easy to find your data. Contact your account team to request access to the beta today!
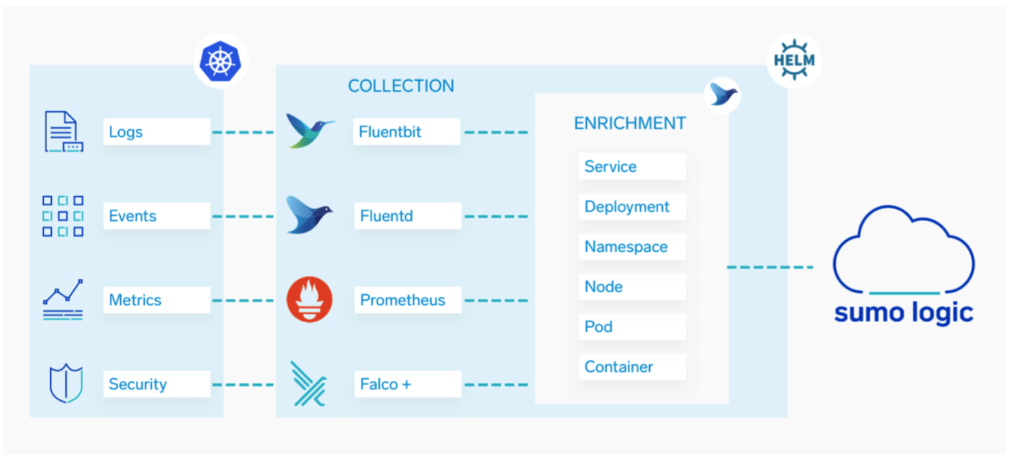
Sumo Logic collects data from your clusters leveraging cloud native technologies tightly coupled with Kubernetes. We collect logs, metrics, events and security events to ensure you have complete observability of your clusters. Sumo Logic enriches these streams with comprehensive metadata. Metadata drives our new Explorer experience and makes it easy to pivot between streams of data.
Log metadata allows customers to freely tag their logs with simple key-value pairs. Any Sumo Logic collector and log source will now support adding key-value pair fields. These fields can be used everywhere in Sumo Logic, from searching logs and to securing access to your logs via RBAC. A new fields management page brings proper managements of all fields, whether they were created from our new log metadata capability or field extraction rules. Log metadata is integral to our new collection process for Kubernetes. Sumo Logic automatically captures well known metadata such as pod, container, namesplace, cluster service and deployment with your log streams via the new log metadata feature.
Metrics Transformation rules enable you to aggregate and transform your raw time series data into new time series. In addition, it provides the flexibility in the retention of original and newly transformed data. Transformation Rules give you the control to assign a value to your time series data. You can keep high cardinality, high volume data for a shorter retention period and aggregate the raw data to higher level business KPIs for long term trending and storage.
Observability of Kubernetes is not just about being able to monitor and troubleshoot. You cannot have an observable system without understanding the security of it as well. Sumo Logic is the first DevSecOps platform that delivers continuous intelligence for your Kubernetes clusters with security built right in. Sumo Logic’s solution provides out-of-the-box support for security events with Falco.
We are launching a suite of new apps built for Kubernetes. Our Kubernetes apps are built for wherever Kubernetes is running. We have refreshed our Kubernetes apps for non-managed, Amazon EKS and GKE and we are also introducing a new App for AKS. We have also partnered with the leading vendors in Kubernetes Security and have apps for Aqua, JFrog Xr-Ray, StackRox and Twistlock.
We have also partnered with the leaders in the CI/CD ecosystem and are happy to announce new integrations with Armory and, CircleCI as well. and CodeFresh.

Sumo Logic is the first DevSecOps platform that delivers continuous intelligence for your Kubernetes clusters no matter where they run. Our solution gives you the discoverability you need to understand your Kubernetes deeply and with the context needed to navigate at the infrastructure and service and application level. The discoverability is powered by comprehensive observability, capturing all the critical signals from Kubernetes and enriching that data with complete metadata. We provide you with integrated security out of the box and through deep integrations with the wider Kubernetes ecosystem. Be sure to check out more details about our Kubernetes Observability Solution, watch a demo, and sign up for a 30-day free trial!
Great, now that we know how we can get this data into Sumo Logic, let’s see these tools in action and start to make this data work for to gain profound insights into everything in our Kubernetes Clusters.
In the third and final post in this series, we will go through the steps to use these tools to collect all of this data into Sumo Logic and show how Sumo Logic can help you monitor and troubleshoot everything in your Kubernetes Cluster.
Monitor, troubleshoot and secure your Kubernetes clusters with Sumo Logic cloud-native SaaS analytics solution for K8s.
Learn more
Principal Product Manager
Frank Reno is a Principal Product Manager at Sumo Logic, where he leads Product for Data Collection. He also serves as Sumo Logic's Open Source Ambassador co-leading all efforts around Open Source. He is also an active contributor to Sumo Logic's open source solutions and the general open source community.
More posts by Frank Reno.

No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.
