
2022 Gartner® Magic Quadrant™ SIEM
Get the report
MoreTrusted by thousands of customers globally.
Browse our library of ebooks, briefs, reports, case studies, webinars & more.
Download your copy today to understand key points
when considering an observability solution.

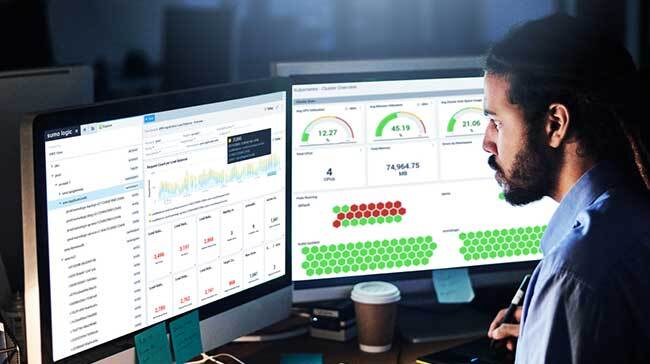
If you run modern workloads—or, for that matter, if you run legacy workloads that you need to manage with any degree of efficiency and scale—you need an observability platform.
We created this guide to help buyers understand the types of observability solutions out there and identify the key considerations when assessing their options. In the guide, you’ll find actionable advice on navigating the complex and rapidly evolving observability market to choose the solution best suited to your business’s needs. Topics covered:
There are dozens of observability solutions on the market today. Good solutions deliver an excellent experience for their users via automations that make data easy to process and understand. They are designed to scale and provide maximum flexibility and integrations so that users can tailor the solutions to their needs. Just as important, they deliver cost-effective observability without hidden or indirect fees.
Download your copy today!

Get in touch with a Sumo Logic rep and start working smarter.

No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.
